

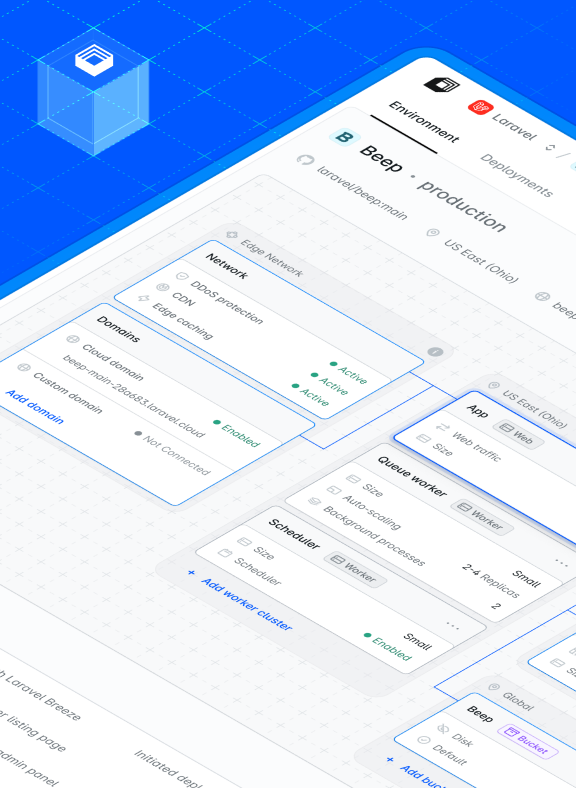
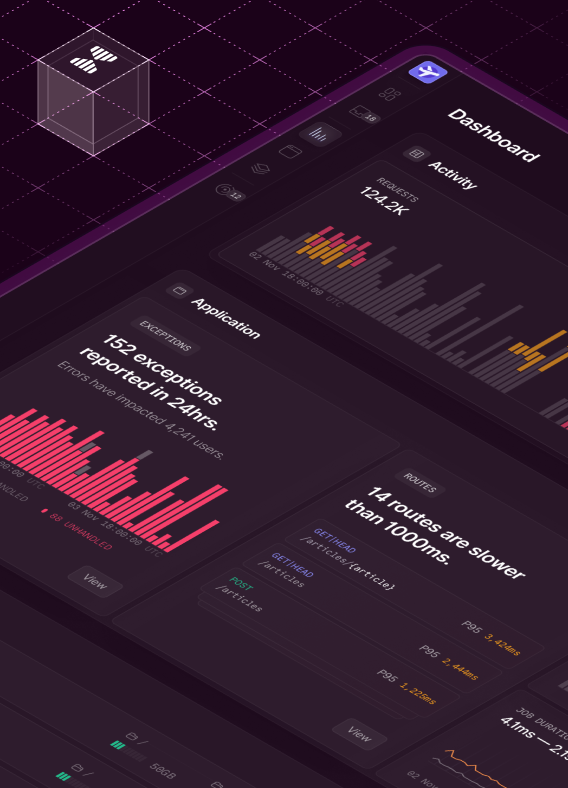
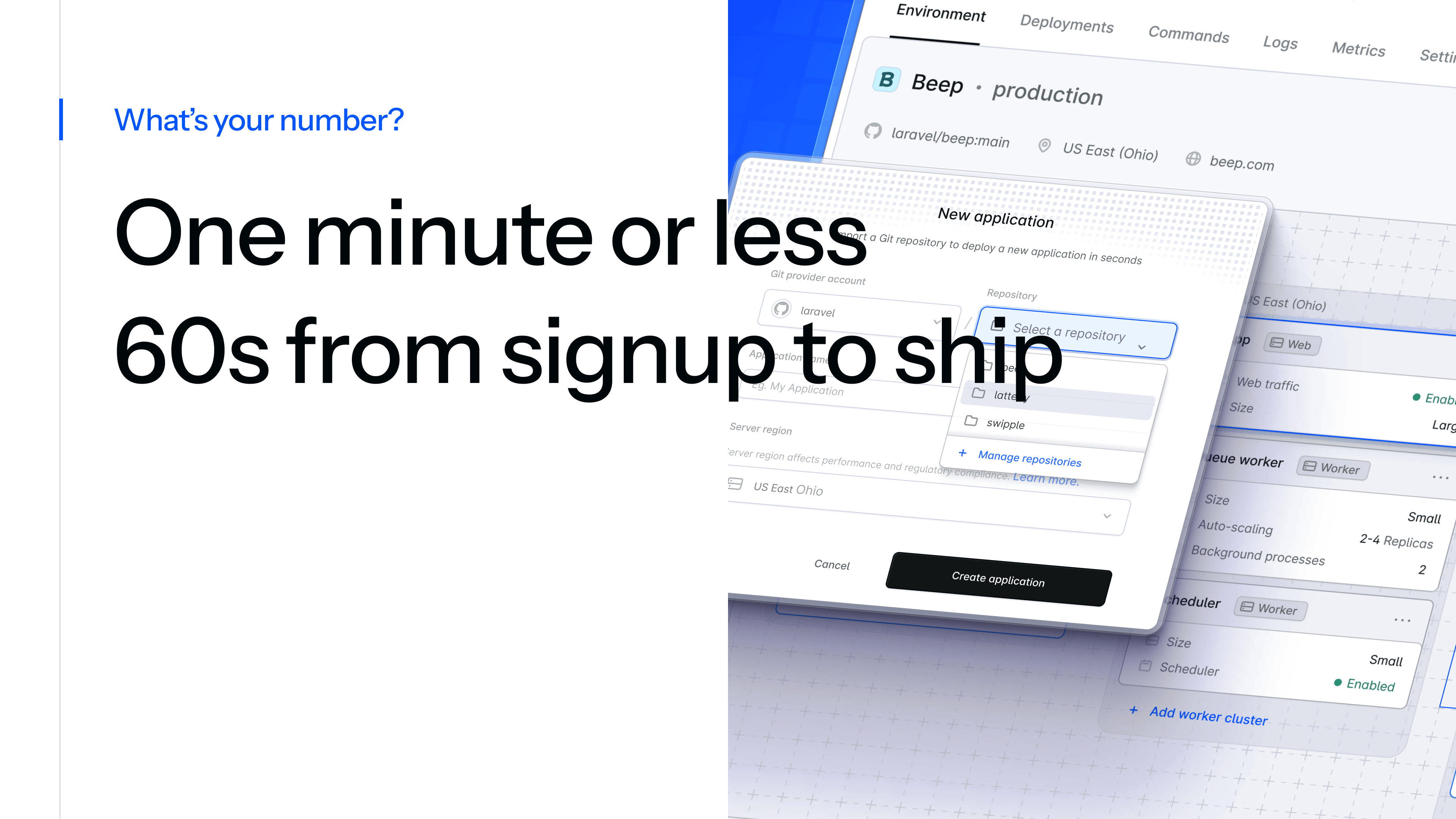
It was Laracon EU, February 2024, at Hannekes Boom in Amsterdam. Over dinner, I sat with Taylor to discuss the then-theoretical Laravel Cloud. “What’s your number?” I asked.
His answer was brutal and simple: one minute or less. From the moment a user signs up to the instant their Laravel app is live on a URL, he wanted it to be under 60 seconds.
From signing in to shipping. From “Hello World” to “Hello Web.” One minute or less.
That became our North Star. There were no compromises as we built Laravel’s first-ever fully managed platform, and the fastest way to deploy and scale Laravel applications.
Building Laravel Cloud: From PoC Sprint to GA
A month later, we kicked off with a razor‑sharp goal to prove the concept: Could we connect a GitHub repo, click deploy, build the app, run it somewhere, and view it in the browser? That would become our focus for the next several months.
We split into three micro‑teams (web app, build service, compute), each owned by a single engineer. Within weeks, and after much discussion (more on that later), we had a working demo and a clear three-milestone path to launch.
Announcing Laravel Cloud at Laravel U.S.
The first milestone was a big one: announce Laravel Cloud to the world at Laravel’s flagship conference, Laracon U.S. in Dallas.
Just four short months after commit one, we screened a polished demo, showing how easy it would be for users to deploy and scale their Laravel applications. Setting this milestone would also serve as a catalyst for growing the team, adding support from product management and design, as well as bolstering the engineering team.
Engineering split into app and infrastructure teams. The app team was responsible for building the web application and user interface, while the infrastructure team had ownership of everything related to running customer workloads.
The split didn’t mean we worked in silos. It was quite the opposite; we continued to move as one cohesive unit with almost every new feature involving a combination of product, design, app, and infrastructure. To align the teams, we ran in two-week cycles with weekly all-hands team meetings. Although the team has grown again (from 3 to 18 people), the structure largely remains the same.
Phased Early Access
 It would be a long road to GA, and we knew we would need real-world testing by early adopters to help kick the tires and iron out any rough edges. In the autumn of 2024, we invited a handful of trusted users for candid feedback.
It would be a long road to GA, and we knew we would need real-world testing by early adopters to help kick the tires and iron out any rough edges. In the autumn of 2024, we invited a handful of trusted users for candid feedback.
As we iterated, we opened spots from our waitlist whose requirements were a good match for the feature set we already had in place. We expanded early access to that cohort over the next several months, acting on feedback as we improved the platform.
General Availability
We had no fixed launch date, just a relentless cadence of data‑driven improvements, aiming for early 2025. As we navigated through early access and confidence levels continued to build, a launch plan began to take shape. We’d announce our launch date at Laracon EU in Amsterdam, with the launch scheduled for three weeks later.
We took the opportunity to bring the team together for a short hackathon in the lead-up to the conference to work on some new features and add some polish. As a fully remote team, this was great. We worked from a prioritized checklist in a Notion doc and, fueled with Coke Zero, made some incredible progress.
Less than one year after the first commit, Laravel Cloud would launch on February 24, 2025.
Building Laravel Cloud: Architecture
A platform like Laravel Cloud has numerous moving parts, so making the correct architectural choices was (and continues to be) paramount. In most cases, this is not straightforward.
We’ve been building products to deploy and host Laravel applications for over 10 years, so we’re very well placed to know the most important features for Cloud. However, building a managed platform comes with a whole new set of unknowns, challenges, and questions.
Infrastructure: Why AWS and Kubernetes
Infrastructure is the unsung hero of Laravel Cloud. It’s the part nobody sees, but it’s very much the engine room making the whole thing possible.
The first iteration of Cloud was always going to be built on a public cloud, and choosing our hyperscaler was easy. AWS is the platform we’re most familiar with, and with its high market share, choosing it gave us the best opportunities for partnerships and private networking with external customer services and potential partners later down the road.
But compute was a tougher call. Lambda, a serverless compute environment provided by AWS, seemed tempting after five years of Vapor, but the difference with Vapor is that we deploy directly into a customer’s AWS account. In theory, Lambda could scale infinitely to suit our needs, but we know from experience that there are some limitations requiring customers to architect their applications differently.
Generous execution time and file upload limits, support for all queue drivers supported by Laravel, and the ability to execute long-running background processes were table stakes for Cloud. Not something Lambda could support.
We turned to Kubernetes on EKS as the compute foundation for Laravel Cloud. A decision that is really paying off. If you’re not aware, Kubernetes is a container orchestration platform that (mostly) automates the deployment, management, and scaling of containerized applications. EC2 nodes and pods give us the self-healing, multi-tenant foundation we need.
The top-level entity in Kubernetes is a cluster. A cluster consists of a control plane and one or more worker machines, known as nodes. Each node runs pods, which host the application workloads.
In the context of Laravel Cloud, this roughly translates to:
- Cluster: EKS (managed Kubernetes from AWS)
- Nodes: EC2
- Pods: Containerized customer applications
We’d landed on a tech stack, now on to the small (heh) task of implementing it.
Account Sharding to Beat AWS Limits
 One foundation we needed to get right from the get-go was AWS account sharding.
One foundation we needed to get right from the get-go was AWS account sharding.
What is account sharding? Running infrastructure at the scale of Laravel Cloud would mean we would very quickly run into AWS account quota limits if we tried to run everything in a single account. We’re talking vCPUs, ECR repos, S3 buckets, and more.
After many iterations, we settled on one account per EKS cluster plus ancillary accounts per region for networking, tooling, logging, and builds. This strategy pools resources and limits the blast radius if an account is paused, ensuring we won’t run out of the resources we care about.
Networking
 With account sharding in place, the next challenge was networking.
With account sharding in place, the next challenge was networking.
How do we support a growing number of Kubernetes clusters running an unbounded number of customer workloads?
How do those clusters talk to the internal services we’re building over time?
How do we manage secure access and permissions at scale?
We decided to provision our VPC in a separate AWS account and share it with cluster accounts via Resource Access Manager (RAM). The decision to use IPv6 was key: It removes IP exhaustion from the equation and makes the whole setup scalable by default.
For accounts that need their own VPC, we connect them to the networking account using Transit Gateway or VPC peering.
Routing
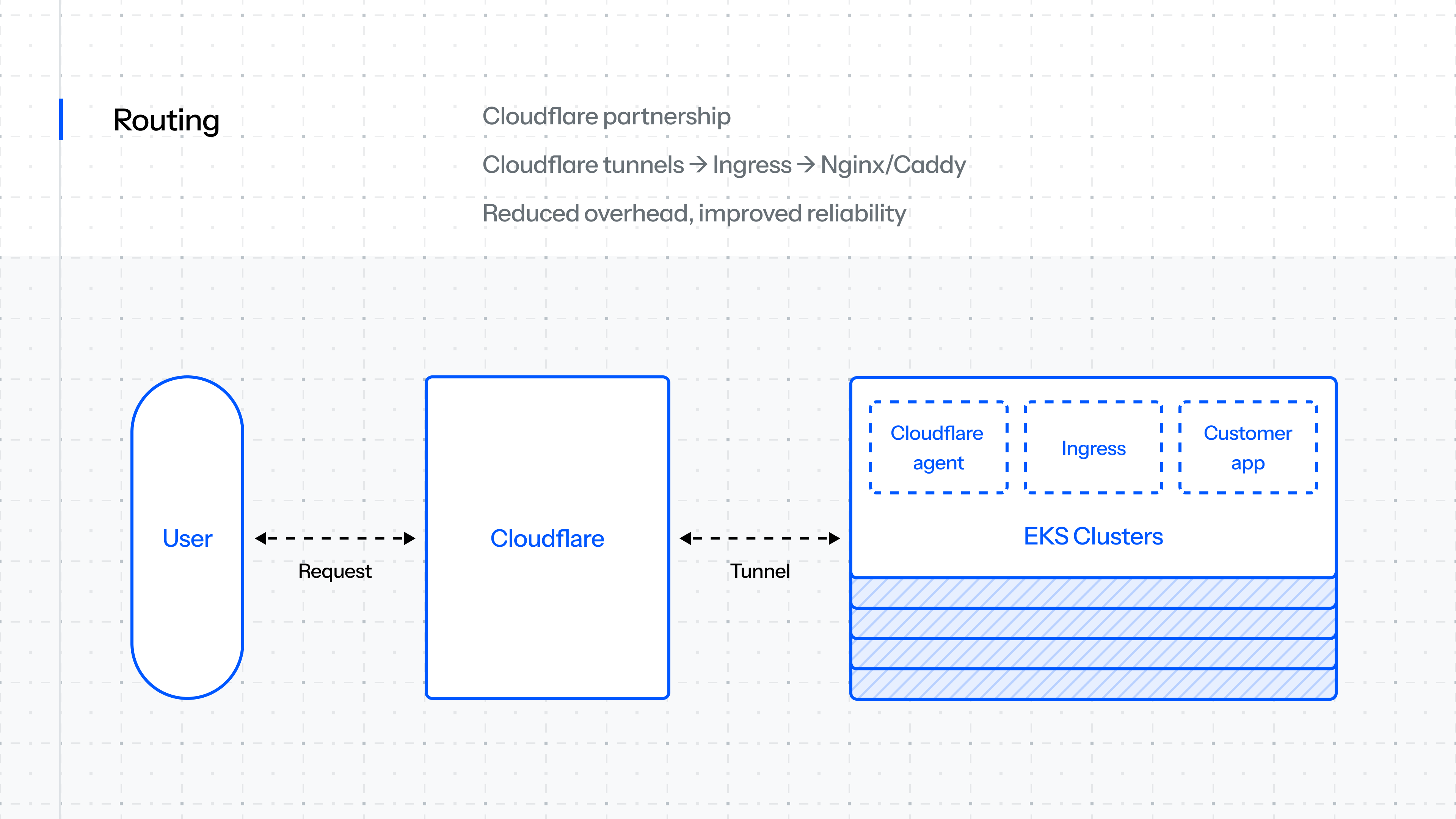 We decided early on to partner with Cloudflare for edge networking. All requests into Laravel Cloud would route through Cloudflare’s network, leveraging its DDoS protection, caching, and security features. It felt good to make that decision up front, and we were confident it would pay off.
We decided early on to partner with Cloudflare for edge networking. All requests into Laravel Cloud would route through Cloudflare’s network, leveraging its DDoS protection, caching, and security features. It felt good to make that decision up front, and we were confident it would pay off.
However, one major problem remained: How do we route each Cloudflare request to the correct Kubernetes cluster that is running a customer’s application?
Well, that turned out to be quite the journey!
We planned to build a custom routing layer within our infrastructure. That meant multiple network load balancers, an autoscaling group of EC2 instances running Nginx, and a key-value store to map hostnames to applications, all before proxying the request to the right cluster.
We wired the whole thing up. It worked end-to-end. We were ready for production… until we ran into issues with mTLS termination.
During a support call, Ethan Kennedy from Cloudflare mentioned “Cloudflare tunnels.” We knew about tunnels, but didn’t realize they could work in our setup. A Cloudflare tunnel acts like a VPN between their network and ours. We run the Cloudflare agent in each Kubernetes cluster, which establishes a private connection and exposes an endpoint we use as the origin for our custom and Cloud domains.
That call gave us the opportunity to drop our entire homegrown routing layer for a proven, zero-maintenance alternative. A big win, thanks to the Cloudflare partnership.
From there, the Cloudflare agent hands off requests to our internal router (an Nginx-based proxy), which forwards traffic to the customer’s application. That application handles the request using either Nginx (standard runtime) or Caddy (Octane runtime).
Customer Workloads
We’ve already covered how customer workloads run on Kubernetes. But how does a user’s configuration in the Laravel Cloud UI translate into Kubernetes API calls? How do we provision app and worker clusters? Handle autoscaling? Start background processes?
It’s not magic, but it might as well be.
When a customer configures an environment and clicks "Deploy," the web app sends a job to an SQS FIFO (Simple Queue Service, First-In, First-Out). That’s where the infrastructure process begins.
A Go-based Kubernetes operator (internally called the “App Operator”) picks up the job. Operators are a design pattern for managing applications on Kubernetes. Ours takes the job from the queue and starts the deployment: cloning the repo, installing dependencies, running build commands, baking everything into a Docker image, and storing it in ECR (Elastic Container Registry).
Once the build completes, the operator pulls the full desired state of the environment from an internal API, generates a Kubernetes deployment object, and applies it. At that point, Kubernetes takes over.
The App Operator also runs a reconcile loop. It fetches state from our internal API (backed by our database), compares it to the running cluster, and resolves any mismatches to keep environments in sync.
When a container initializes, a small Go process called cloud-init bootstraps the container and manages any customer-defined background processes.
Autoscaling and hibernation are event-driven, triggered by the customer’s applications and acting on them accordingly.
For autoscaling, we monitor CPU and memory usage and scale within customer-defined thresholds.
For hibernation, we track idle time between HTTP requests. If it exceeds the configured timeout, we scale the workload to zero. When the next request comes in, Kubernetes re-provisions the workload. There’s a cold-start penalty, but for many customers, it’s worth the savings.
Databases
Our original plan was to launch Laravel Cloud with serverless Postgres as the only database option. As GA approached, we decided it was too limiting not to offer MySQL on day one.
So we accelerated the development of Laravel MySQL. To be clear, we had always planned to build a MySQL offering, but initially envisioned it as a fast follow-up after launch.
Much like our app compute, Laravel MySQL is built on Kubernetes. We reused lessons and patterns from the App Operator and leaned on some of the same patterns to develop our MySQL Operator.
When a user creates or modifies a database through the UI, a job is pushed onto a queue. The MySQL Operator picks it up, pings an internal API for the full database spec, then applies the configuration via the Kubernetes API.
Since databases have state, each one is backed by an EBS volume. The operator handles snapshots (daily and manual) and will manage point-in-time recovery when this feature ships later this year.
The operator pattern is one we are enjoying and continue to get a lot of value from. We’ll continue to invest in developing our operator tooling to unlock more opportunities moving forward.
Observability
Our observability dashboard gives us a clear view of platform health. It helps us spot trends, investigate customer issues, and respond quickly when problems arise.
It’s a tool we have spent, and continue to spend, time developing dashboards and queries to help surface the information we need to better understand our performance, bottlenecks, and issues.
After evaluating several options, we landed on Grafana Cloud. It gave us solid tooling out of the box while allowing for custom metrics specific to our platform.
But the real reason we chose Grafana Cloud was flexibility. We know that at a certain scale, the cost and constraints of a hosted observability platform won’t make sense. When that day comes, we’ll likely look to bring it in-house. Staying within the Grafana ecosystem means we’ll have a smooth path to migrating to self-hosted Grafana when the time comes.
Five Months Later: Over 740K Deployments
This is just the architecture side of the story. For more on how we built Laravel Cloud, read our upcoming stories on how we developed the platform’s web application and customer ecosystem (billing, admin, and more).
Building Laravel Cloud in under a year demanded ruthless focus on our North Star and relentless engineering pragmatism as we grew and worked hard to avoid silos. From the first commit to GA, we learned to pivot fast, from ditching Lambda for Kubernetes and swapping custom routers for Cloudflare tunnels to scaling account shards instead of wrestling quotas.
While still a relatively small team, it’s a lot of puzzle pieces to position while working toward the ambitious goal of launching within one year of breaking ground.
Did we get everything right? No. No team does.
What we have is an incredibly smart, dedicated, and ambitious team that has produced a strong foundation on which we can continue to build and improve. We’ve made smart tradeoffs, stayed pragmatic, and built a platform that’s easy to evolve. We iterate fast and avoid technical debt traps.
We’re a team that cares about the craft and quality of everything we do. Whether it’s user-facing or not, the quality bar does not drop.
Just five months post-launch, we crossed 740,000 deployments: a big milestone and early proof that we’re solving real problems for real teams. I’m incredibly excited to see what the next thousands of deployments will bring.
While extremely challenging, getting Laravel Cloud from zero to one was a whole lot of fun. Of course, running a product used by many thousands of customers brings a whole bunch of new challenges, which we’re already relishing and looking forward to seeing grow from here.
Live in One Minute 30 Seconds or Less
Did we meet our North Star metric?
At Laravel, we care deeply about developer experience, so there is no world where we would have felt it acceptable to launch without doing so.
Of course, we hit that target with a good amount of change. From signing in to shipping. From "Hello World" to "Hello Web." Thirty seconds or less.
What’s next? Scaling further, driving costs down, and expanding our feature set.
If this sounds interesting to you, check out Laravel Cloud. We put a lot of love, effort, and beautiful code into it.